INTRODUCTION
Devanagari is an alphasyllabary, meaning consonant-vowel sequences are written as one unit, as opposed to individual units. In the lesson The Consonant, we explored how consonants behave and how they can be used to build clusters. In this lesson, we will look how we can assign a vowel value to consonants or clusters to form a syllable.
Take the following sample text:
सानो छ आँप, सानो छ कुर्सी, सानै छ जगत्
Accompanying the consonants and vowels are these dashes, points and curves around the letters. These marks are important, as they indicate the accompanying vowel sounds or other modifications. Such markers that modify a letter to the alter the sound are called diacritics. Each vowel has its own diacritic mark except अ (a), as it simply removes the halanta instead. These diacritics can go above, below, before or after the character.
An important thing to remember is that a character can only carry one vowel diacritic (consonant diacritics can be added, however). You cannot add diacritics to vowel letters as well, because they’re sounds in their own right.
HALANTA (RECAP)
We have previously seen the halanta in the lesson The Consonant. Just to recap, it is attached to a consonant to indicate the absence of a vowel sound. It is sometimes called the ‘killer stroke’, since it ‘kills’ any vowel sound attached to the character. For example, ‘न’ is pronounced as ‘na’ but with a हलन्त (halanta), it turns into न् (n).
When we modify a consonant by adding a vowel diacritic to it, the halanta is removed and a vowel diacritic is added.
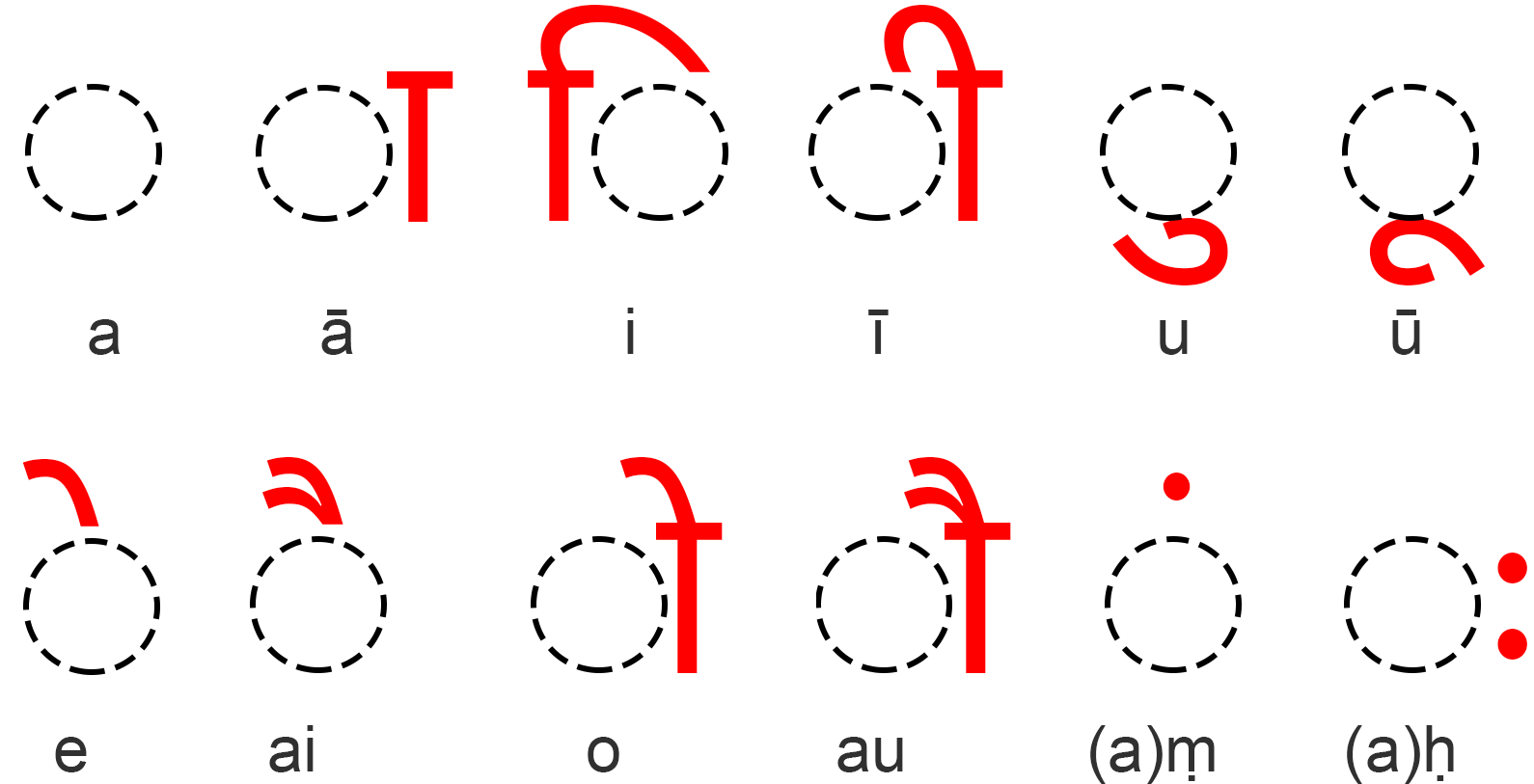
VOWEL DIACRITICS CHART
Note | The dotted circle indicates where the character goes.
PROCESS
Let’s say you want to make the syllable ‘ni’. How would you do it? In English, you might do it as:
n + i = ni
In Devanagari, the process is simple: you take the corresponding vowel diacritic (in this case, ‘ ि ’ for ‘i’) and add it to the consonant (in this case, ‘न्’ for ‘n’), with its location depending on where it should be placed as based on the chart above (in this case, before the consonant). Note that the halanta has to be removed, as it only serves to indicate the absence of a vowel sound. In the end, you should get:
न् (n) + ि (i-diacritic) = नि (ni)
Let’s try a few more examples:
प् (p) + ो (o-diacritic) = पो (po)
ज् (j) + ु (u-diacritic) = जु (ju)
र् (r) + े (e-diacritic) = रे (re)
The process also works for consonant clusters:
म् (m) + क् (k) | म्क् (mk) + े (e-diacritic) = म्के (mke)
प् (p) + ल् (l) + स् (s) + त् (t) | प्ल्स्त् (plst) + ा (ā-dicritic) = प्ल्स्ता (plstā)
Note | अ (a) has no diacritic; simply remove the halanta.
TABLE OF VOWEL DIACRITICS
| अ (a) | none |
| आ (ā) | ा |
| इ (i) | ि |
| ई (ī) | ी |
| उ (u) | ु |
| ऊ (ū) | ू |
| ए (e) | े |
| ऐ (ai) | ै |
| ओ (o) | ो |
| औ (au) | ौ |
Here is an example table showing it works on the consonant प् (p), with the corresponding vowel above:
| Vowel | अ | आ | इ | ई | उ | ऊ | ए | ऐ | ओ | औ |
| IAST | a | ā | i | ī | u | ū | e | ai | o | au |
| Diacritic | ा | ि | ी | ु | ू | े | ै | ो | ौ | |
| Syllable | प | पा | पि | पी | पु | पू | पे | पै | पो | पौ |
| IAST | pa | pā | pi | pī | pu | pū | pe | pai | po | pau |
CONSONANT DIACRITICS
Remember when I told you that the last two diacritics on the diacritics chart are not vowel diacritics but rather consonant diacritics? For some reason, they are traditionally included in the vowel section and sung in the Devanagari alphabet[?] song!
Consonant diacritics are just like vowel diacritics, except they add a ‘consonant’ sound to the consonant. This is not strictly true, as consonants are not always added. Rather, it is helpful to realize them that their function is to change the articulation of the consonant with an aspiration, nasalization or stops.
Unlike vowel diacritics, consonant diacritics do not remove the halanta by themselves, as they are not vowels per se (except ऋ (ṛ), but we’ll get to that). They simply change how the character is articulated. For example, ‘ṃ’ simply adds a slight nasalization in the form of a pronounced न् (n) sound. As such, vowel diacritics need to be added (before the nasalizer) to produce a syllable. Let’s see how this works for अं (ṃ):
घ् (gh) + ं (ṃ-diacritic) = घ्ं (ghṃ)
घ् (gh) + ा (ā-diacritic) + ं (ṃ-diacritic) = घां (ghāṃ) [pronounced like ghān]
Note | The ṃ sound succeeds the consonant(s)-vowel unit. This is true for अँ (m̐/~) and अ: (ḥ) as well, but for ऋ (ṛ), the sound follows the consonant.
There are two more important consonant diacritics. They are अँ (m̐/~) and ऋ (ṛ). अँ (~) simply nasalizes the consonant (think of a stuffy nose voice) while ऋ (ṛ) adds the sound रि (ri) to a consonant. ऋ (ṛ) is also unique in that it comes with its own vowel, so other vowels can’t be added to it. As such, it also requires the removal of the halanta. अँ (~) is also known as ‘candrabindu’. In the image below, you can see the diacritics:
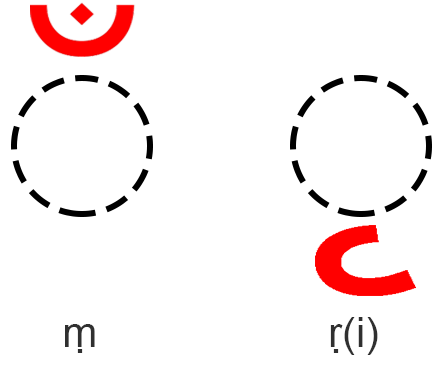
The candrabindu nasalizes any syllable, and it appears on top of the character (or within the sickle sometimes). To nasalize a word, block the airflow to the nasal passage with the back of your tongue. This will give a more nasal voice.
ब् (b) + ा (ā-diacritic) + ँ (m̐-diacritic) = बाँ (bām̐ or bā~)
The above is pronounced like ‘bā’ but with more nasal tone. The way it is transliterated will vary sometimes, with either m̐ or ~, but the pronunciation remains identical. (This is because of how different transliteration softwares parse Devanagari).
चन्द्रबिन्दु (candrabindu) literally means ‘moon dot‘.
ऋ (ṛ) adds a रि (ri) sound to a consonant. Since it already ‘carries’ a vowel sound, other vowels cannot be added and it also removes the halanta.
म् (m) + ृ (ṛ-diacritic) = मृ (mṛ) [pronounced like mri]
We haven’t really talked about अ: (ḥ or :) yet because it’s not really a thing in Nepali. You may see it in some words due to historical orthography reasons, but you can simply ignore it as it carries no pronunciation value. Here is an example:
ब् (b) + ा (ā-diacritic) + ः (ḥ-diacritic) = बा: (bāḥ) [pronounced like bā]
TABLE OF CONSONANT DIACRITICS
| अँ (~) | ँ |
| ऋ (ṛ) | ृ |
| अं (ṃ) | ं |
| अ: (ḥ) | ः |
EXCEPTIONS
While the above applies in almost every case, there are two exceptions. When we combine र् (r) with an ‘u’ or an ‘ū’ sound, we use a different form of diacritic. It looks like a tail and is added between the hinge of the character:
र् (r) + ु (u-diacritic) = रु (ru)
र् (r) + ू (ū-diacritic) = रू (rū)
FORMAL NAMES
The diacritics have formal names that are easy to build. They are simply named after what they sound like, then we add कार (kār). For example, ा (ā-diacritic) is called ākār.
When there is an ambiguity because the two vowels sound the same, then we use the convention of ह्रस्व (hraswa) and दीर्घ (dīrgha). The shorter vowels (i and u) are called ह्रस्व (hraswa) while the longer vowels (ī and ū) are called दीर्घ (dīrgha). Note that these words go before the formal name (e.g. hraswa ukār for ु).
To see how diacritics behave, you can download an Excel sheet below:
EXERCISES
A. WRITE DOWN THE FOLLOWING SYLLABLES IN DEVANAGARI
1. ksai
2. lo
3. rsi
4. kha
5. chyai
B. TRANSLITERATE THE FOLLOWING SYLLABLES
1. स्या
2. त्ल
3. प्री
4. ङ्दे
5. टौ
C. TRANSLITERATE THE FOLLOWING STRING
आँना मेकी आसिकौ मर्ते: गृछलुं भाऊएवो रेँरुअस् पा सर्णाँथो री मेहेहा रे फ्र्क्स्त्टोमिर्सू [text is nonsensical]
ANSWERS
A. 1. क्सै
A. 2. लो
A. 3. र्सि
A. 4. ख
A. 5. च्यै
B. 1. syā
B. 2. tla
B. 3. prī
B. 4. ṅde
B. 5. ṭau
C. ā~nā mekī āsikau marte: gṛchaluṃ bhāūevo re~ruas pā sarṇā~tho rī mehehā re phrkstṭomirsū